

Natural Language Processing (NLP) has undergone significant advancements in recent years, propelled by the availability of scalable computing resources and the expansion of large datasets. Concurrently, extensive language models have demonstrated remarkable few-shot learning capabilities, achieving high accuracy across various NLP datasets without requiring additional finetuning. This progress has led to exponential growth in state-of-the-art NLP models. However, the training of such models presents two main challenges:
- The sheer size of model parameters surpasses the capacity of even the most extensive GPU’s main memory.
- Even if the model could fit into a single GPU (via parameter swapping between host and device memory), the substantial number of required compute operations results in impractical training durations without parallelization. For instance, training a GPT-3 model with 175 billion parameters would take 36 years on eight V100 GPUs or seven months on 512 V100 GPUs.

Streamlining Training on Multiple GPUs
If the pace of model training on a single GPU is too sluggish or the model’s parameters exceed the capacity of a single GPU’s memory, expanding to a multi-GPU configuration becomes a viable alternative. Before making this transition, thoroughly explore the methodologies and tools for efficient training on a Single GPU, as they are universally applicable to model training, regardless of the number of GPUs. After exhausting these strategies on a single GPU and finding them inadequate for your specific case, contemplate the shift to multiple GPUs.
The transition from a single GPU to multiple GPUs necessitates incorporating some form of parallelism to distribute the workload effectively across the available resources. Various techniques can be employed to achieve parallelism, including data parallelism, tensor parallelism, and pipeline parallelism. It’s crucial to acknowledge that there is no one-size-fits-all solution, and the optimal settings depend on the unique hardware configuration at your disposal.
Parallel computing
Parallel computing involves concurrently executing multiple tasks or processes using diverse computing resources, such as multiple processors or computer nodes, to address a computational problem. This technique aims to improve computation performance and efficiency by dividing a complex operation into smaller sub-tasks that can be processed simultaneously.
In parallel computing, tasks are decomposed into smaller components, and each component runs concurrently on distinct computer resources. These resources may include separate processing cores within a single computer, a network of computers, or specialized high-performance computing platforms.
Various frameworks and programming models have been established to facilitate parallel computing, providing abstractions and tools that simplify the design and implementation of parallel algorithms. Commonly employed programming models include:
- Message Passing Interface (MPI): MPI is widely used for developing parallel computing systems, particularly in distributed memory scenarios. It facilitates communication and collaboration between different processes through message passing.
- CUDA: Developed by NVIDIA, CUDA serves as a platform and a programming language for parallel computing. It empowers programmers to harness the full potential of general-purpose parallel computing using NVIDIA GPUs.
- OpenMP: A popular approach for shared memory parallel programming, OpenMP allows programmers to delineate parallel segments in their code. These segments are then executed by multiple threads running on different processors.
Distributed deep learning involves employing a distributed system with multiple workers to execute deep learning inference or training. Since the mid-2010s, there has been a focus on enhancing deep learning through scale-out strategies, leading to distributed deep learning. One well-known architecture in this context is the parameter server.
Recently, various parallelization mechanisms have emerged for distributing computations across multiple workers. Initially, data parallelism, which involves dividing batches into microbatches, was introduced and aligns with the parameter server architecture. However, additional parallelisms, including tensor and (pipeline) model parallelism, are now in use.
This post explores three types of parallelism: data parallelism, tensor parallelism, and pipeline parallelism. To ensure clarity throughout the post, the following terms are consistently employed:
- Parameters: Refers to the weights of model layers.
- Output: Denotes the results of the forward pass.
- Gradients: Signifies the outcomes of backward propagation.
Data parallelism involves dividing a large batch into several microbatches and distributing it among multiple workers.
To optimize accelerator utilization, batch size needs to be increased. However, this can pose a challenge as the large volume of inputs and computed outputs may exceed the accelerator’s memory capacity. Data parallelism addresses this issue by dividing the batch into N slices, allowing each accelerator to handle only 1/N inputs and generate 1/N outputs.

In data parallelism, parameters (weights) are replicated across all accelerators and execute the exact computations collectively. In cases where synchronous stochastic gradient (SGD) training is employed, backpropagation results or gradients must be aggregated, and parameters need updating. This can be achieved through the parameter server architecture or the more recent all-reduce method introduced by Baidu.
Data parallelism is a widely adopted technique to accelerate the training process when dealing with substantial mini-batches that are too large to fit on a single GPU. Remember, in the previous post about GPUs and threads, we want to utilize as many threads and memory as possible on the GPU itself. However, GPUs have finite memory and threads, and we want to eliminate the use of the PCIe bus and keep the computations and the data on the GPU. In data parallelism, the approach involves breaking down a mini-batch into smaller-sized batches, each of which can comfortably fit into the memory of different GPUs within a single computer or multiple computers on the network.
Subsequently, the adjusted parameters are transmitted to each GPU, and the entire process is iterated for a new mini-batch. This cyclic process ensures that each GPU consistently processes distinct data portions, enhancing overall computational efficiency. The visual representation of this workflow is depicted in the accompanying diagram.

In this setup, each GPU maintains an identical copy of the network parameters and independently executes both the forward and backward passes for its designated portion of the mini-batch. Following the completion of the backward pass, the GPU communicates the calculated gradients to a central parameter server. The primary role of the parameter server is to aggregate these gradients and compute updates to the network parameters, typically employing a variant of Stochastic Gradient Descent.
Tensor parallelism
Tensor parallelism is a sophisticated technique employed in deep learning, specifically for large-scale models such as transformers. In this approach, individual layers of the model are horizontally sharded into smaller, independent blocks of computation. The objective is to distribute these computation blocks across different devices, allowing concurrent execution and parallel processing.

In the context of transformers, attention blocks and multi-layer perceptron (MLP) layers are pivotal components that can significantly benefit from tensor parallelism. Let’s delve into these components to understand how tensor parallelism is applied:
- Attention Blocks:
- Attention blocks are crucial in transformer architectures, enabling the model to weigh different parts of the input sequence differently.
- With tensor parallelism, the attention blocks can be divided into smaller, independent sections. Each of these sections is to different devices for simultaneous computation.
- For instance, in multi-head attention blocks, where attention is applied across multiple heads or groups of heads, each head or group can be assigned to a distinct device. This allows for parallel and independent computation, enhancing overall efficiency.
- Multi-Layer Perceptron (MLP) Layers:
- MLP layers are another integral part of transformer models, capturing complex, non-linear relationships in the data.
- Tensor parallelism can be applied to shatter the MLP layers into smaller, manageable blocks. These blocks can be distributed across various devices for parallel processing.
- By executing these computations independently on different devices, tensor parallelism accelerates the training and inference processes.
In essence, tensor parallelism optimizes the utilization of diverse computational resources by breaking down model layers into smaller, manageable units. This approach enhances the overall efficiency of training large-scale models like transformers, contributing to faster and more scalable deep learning processes.
Pipeline Parallelism
Deep neural networks are structured as layers comprising a forward computation function and associated parameters. The model’s size is determined in each layer. For large networks to determine the model’s size and passing local memory limits, model parallelism is employed, distributing portions across different machines. Parameters are balanced per layer on corresponding machines. However, standard model parallelism often under-utilizes computing resources and lacks clarity in optimal model distribution for enhanced performance.

Pipeline parallelism is a training strategy that capitalizes on parallelism in the pipeline during training. The training examples are initially partitioned into small batches, called micro-batches in GPipe and mini-batches in PipeDream. Subsequently, the execution of each set of small batches is pipelined across cells, employing either inter-batch or intra-batch parallelism. The efficacy of pipeline parallelism is gauged by assessing total memory usage and pipeline utilization. Pipeline utilization, denoted as Util, signifies the percentage of pipeline stages that remain active and not idle or stalled at any given time. Similar to data parallelism, pipeline parallelism encompasses both synchronous and asynchronous pipelines, each distinguished by their distinct update policies.

3D parallelism
Topology-aware 3D mapping, as illustrated in Figure 2, involves meticulously aligning each dimension in 3D parallelism with workers to optimize compute efficiency. This strategy leverages two fundamental architectural properties:
- Optimizing for Intra- and Inter-Node Communication Bandwidth:
- Model Parallelism Prioritization: Model parallelism exhibits the highest communication overhead among the three strategies. To mitigate this, emphasis is placed on arranging model parallel groups within a node, capitalizing on the larger intra-node bandwidth. The NVIDIA Megatron-LM tensor-slicing style of model parallelism is implemented for this purpose.
- Data Parallel Group Placement: When model parallelism doesn’t span all workers in a node, data-parallel groups are positioned within the node. Conversely, if model parallelism spans all workers, data-parallel groups are placed across nodes.
- Pipeline Parallelism Placement: Given its low communication volume, pipeline parallelism allows the scheduling of pipeline stages across nodes without being constrained by communication bandwidth limitations.
- Bandwidth Amplification via Parallelism in Communication:
- Decreased Communication Volume: Both pipeline and model parallelism result in a linear decrease in the size of gradients communicated by each data parallel group. Consequently, the overall communication volume is reduced compared to pure data parallelism.
- Independent and Parallel Communication: Each data parallel group independently and concurrently performs communication among a subset of localized workers. This approach enhances adequate bandwidth for data-parallel communication by combining reduced communication volume with increased locality and parallelism.


Various types of parallelism

Distributed Computing
The demand for artificial intelligence has surged due to advances in machine learning and hardware acceleration. However, training larger models, like neural networks, requires substantial data, surpassing the processing power of individual machines. There’s a need for distributed systems to address this, posing challenges in efficiently parallelizing training processes and maintaining model coherence.
Scale-out designs, often observed in high-performance computing (HPC), offer advantages over strategies to enhance the processing power of a single machine in large-scale machine learning. These advantages include lower equipment costs, increased resilience against failures, and improved aggregate I/O bandwidth. Scaling out effectively reduces the impact of I/O on workload performance, particularly in data-intensive tasks like ML model training. However, not all ML algorithms are suitable for distributed computing models, limiting the applicability of scale-out.
The distinction between traditional supercomputers, grids, and the cloud has become less clear for demanding workloads like machine learning, with GPUs and accelerators increasingly prevalent in major cloud data centers. Achieving acceptable large-scale performance now requires prioritizing the parallelization of machine learning workloads. However, shifting from a centralized solution to a distributed system introduces typical challenges such as performance, scalability, failure resilience, and security. Below is a sampling of toolsets used today to manage distributed computing for AI/ML workloads.

A distributed system is a network of independent computer systems connected by centralized software commonly used in applications like online gaming, web services, and cloud computing. However, designing a distributed system involves several critical considerations:
- Heterogeneity:
- Definition: Refers to differences in network, hardware, operating system, and developer implementations.
- Fundamental Component: Middleware serves as a set of services facilitating interaction across diverse components in a client-server environment.
- Openness:
- Characteristics: Open systems allow the creation of new resource-sharing services with published interfaces, promoting uniform communication mechanisms across varied hardware and software.
- Scalability:
- Objective: Maintain efficient performance as the system expands in terms of users and resources as the system expands. As the system expands
- Considerations: As the system expands, factors include size, geography, and management, aiming for consistent performance regardless of system size.
- Security:
- Components: Emphasizes confidentiality, integrity, and availability in information systems.
- Measure: Encryption safeguards shared resources and secure sensitive information during transmission.
- Failure Handling:
- Challenge: Address partial failures in both hardware and software components.
- Implementation: Corrective measures are essential to manage faults and prevent incorrect results or premature termination of computations.
- Concurrency:
- Scenario: Multiple clients accessing shared resources simultaneously, involving read, write, and update operations.
- Requirement: Ensuring the safety of each resource in a concurrent environment, preventing conflicts and inconsistencies.
- Transparency:
- Objective: Present the distributed system as a unified entity, concealing the underlying autonomy of individual systems.
- Expectation: Users or application programmers should experience transparency in service locations, with seamless transitions between local and remote machines.
The system architecture for a distributed system depends on the use case and the expectation we’ve from it. However, there are some general patterns that we can find in most of the cases. In fact, these are the core distribution models that the architecture adopts:
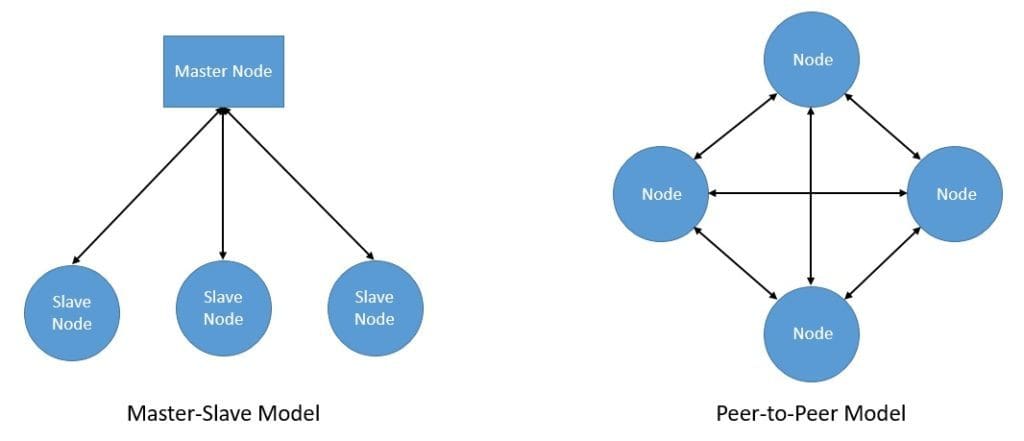
- Master-slave: In this model, one node of the distributed system plays the role of master. Here, the master node has complete information about the system and controls the decision-making. The rest of the nodes act as salves and perform tasks assigned to them by the master. Further, for fault tolerance, the master node can have redundant standbys.
- Peer-to-peer: There is no single master designated amongst the nodes in a distributed system in this model. All the nodes equally communicate the responsibility of the master. Hence, we also know this as the multi-master or the masterless model at the cost of increased complexity and communication overhead.
While both these architectures have their own pros and cons, it’s unnecessary to choose only one. Many of the distributed systems actually create an architecture that combines elements of both models.
A peer-to-peer model can provide data distribution, while a master-slave model can replicate data in the same architecture.
Storage needs for AI/ML workloads
AI applications demand high-performance storage networking to handle extensive data efficiently and intensive processing efficiently. We must develop networking platforms with high-bandwidth connections, low latency, and parallel data access for rapid and effective data retrieval. For scalability, consider storage solutions like distributed file systems or object storage that can accommodate the growing data volume applications performance requirements of AI applications.
High-speed data retrieval, parallel data access, caching mechanisms, and support for distributed storage systems to ensure optimal data accessibility and faster AI processing. Choose storage networking solutions that meet unique data management needs, offering efficient data movement, data virtualization, support for replication and backup, and integration with collaboration tools to streamline processes and enhance teamwork within AI teams. For applications adopting hybrid or multi-cloud architectures, select storage networking that seamlessly integrates with both on-premises infrastructure and cloud storage services, facilitating efficient data movement, synchronization, and collaboration.
A well-designed automated machine learning (ML) pipeline should be equipped with an adequate storage capacity tailored to the specific data requirements of the employed models. Models with substantial data needs, such as those that consume Petabytes of storage, necessitate careful consideration of where this storage should be situated – whether on-premises or in the cloud.
Preferably, the storage should be colocated with the training process. For instance, if utilizing TPUs on Google Cloud for training, it is advisable to leverage Google Cloud Storage for storing data due to its limitless scalability. Alternatively, if opting for local NVIDIA GPUs for training, employing a high-performance, large-volume, fast-distributed file system for local data storage is recommended. In cases where a hybrid infrastructure is established, meticulous planning of data ingestion is essential to avert potential delays and complexities during the training phase.
Lastly, prioritize storage solutions with robust security measures, including encryption, access controls, and mechanisms such as replication, snapshots, and backup, to ensure sensitive AI data sets’ confidentiality, integrity, and availability.
Networking needs for AI/ML workloads
In the evolving landscape of AI/ML clusters, the networking industry must adapt to scalable and sustainable networks. Traditionally, separate InfiniBand networks were used based on workload or processor technology, but a current trend involves consolidating networks using Converged/Lossless Ethernet for smaller AI/ML clusters. Future-proofing for large-scale clusters involves advancing Ethernet to a preferred networking protocol, with 400/800G networks and innovations like distributed scheduled fabrics (DSF) enhancing Ethernet’s capabilities.
Handling large datasets in AI/ML workloads is challenging, and while GPUs accelerate computations, data and model sizes, especially in Large Language Models (LLMs), often surpass a single GPU’s capacity. Multiple GPUs are commonly required, and strategies vary across frameworks, distributing data across GPU node clusters.
The cost of an AI data center is heavily influenced by GPU numbers. To maximize GPU utilization, a high-performance GPU node network is crucial. RDMA approaches from the HPC community are prevalent, enabling zero-copy transfers between remote GPU node memory, initially designed for InfiniBand, with stringent requirements.
Ethernet-based networks, particularly RDMA over Converged Ethernet version 2 (ROCEv2), are gaining traction in AI/ML training clusters as an alternative to InfiniBand. ROCEv2 uses Priority-based Flow Control (PFC) for lossless packet delivery, addressing challenges with techniques like Data Center Quantized Congestion Notification (DCQCN).
In typical Clos topology of Ethernet fabrics, congestion challenges may occur between leaf and spine switches. Traditional Equal-Cost Multipath (ECMP) methods may result in suboptimal network utilization, congestion, and packet drops, particularly for long-lived high-bandwidth flows. Efforts to enhance network utilization include emerging techniques like Dynamic Load Balancing (DLB) and packet spraying. However, challenges adapting RDMA to Ethernet impact communication performance, necessitating solutions like DCQCN or RCM.
Accurately setting thresholds for PFC and ECN in DCQCN remains challenging. Achieving optimal network utilization requires load balancing and motivates endpoint enhancements for improved solutions.
Summary
We have learned the importance of optimizing model training, especially in scenarios where a single GPU may be insufficient due to a slow training pace or model size exceeding GPU memory capacity. The transition to multi-GPU configurations is suggested, with a recommendation to explore efficient training methodologies on a single GPU first.
Various forms of parallelism, such as data parallelism, tensor parallelism, and pipeline parallelism, are discussed to distribute workloads effectively across multiple GPUs. Parallel computing, frameworks like MPI, CUDA, and OpenMP, as well as distributed deep learning with parameter servers, are explored to enhance computational performance.
Distributed computing tools for managing AI/ML workloads in distributed systems are introduced, emphasizing the challenges and considerations involved in designing such systems. Key aspects include heterogeneity, openness, scalability, security, failure handling, concurrency, and transparency.
Storage needs for AI/ML workloads were discussed, emphasizing high-performance storage networking with features like high-speed data retrieval, parallel data access, caching mechanisms, and support for distributed storage systems.
Networking needs for AI/ML workloads are explored, noting the industry’s adaptation to scalable and sustainable networks, the shift from separate InfiniBand networks to consolidated Converged/Lossless Ethernet networks, and the importance of high-performance GPU node networks. Challenges in handling large datasets and strategies for distributing data across GPU node clusters are highlighted, with a focus on emerging technologies like RDMA over Converged Ethernet version 2 (ROCEv2) and techniques like Data Center Quantized Congestion Notification (DCQCN) to address networking challenges.
In summary, a comprehensive overview of considerations and strategies for optimizing the training of machine learning models, covering parallelism, distributed computing, storage, and networking needs in the context of AI/ML workloads.
